


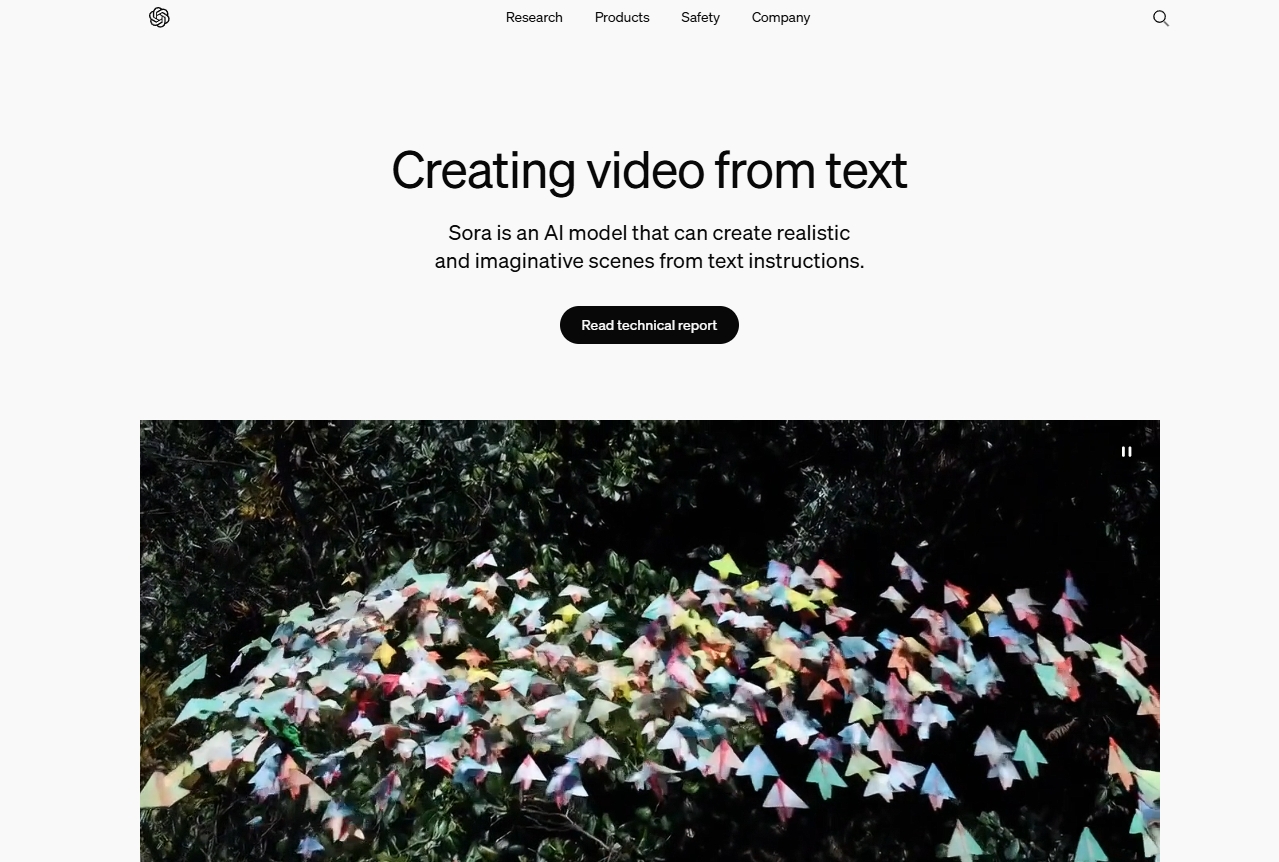
简介
Sora是由OpenAI研发的AI视频生成模型,它具备将文本描述转化为视频的能力,专注于创造出既逼真又富有想象力的视频场景。Sora旨在模拟现实世界的物理运动,帮助解决需要现实世界互动的问题,并提供长达一分钟的视频生成能力,同时保持视觉质量和对用户输入的高度还原。
主要功能
文本驱动的视频生成:根据用户提供的详细文本描述生成视频内容,涵盖场景、角色、动作、情感等元素。
视频质量与忠实度:生成的视频保持高质量视觉效果,并且紧密遵循用户的文本提示。
模拟物理世界:Sora模拟现实世界的运动和物理规律,增强视频的逼真度。
多角色与复杂场景处理:能够处理包含多个角色和复杂背景的视频生成任务。
视频扩展与补全:基于现有静态图像或视频片段进行动画制作或延长视频长度。
主要特点
技术架构:包括文本条件生成、视觉块、视频压缩网络、空间时间块、扩散模型(基于Transformer架构的DiT模型)、Transformer架构等,这些技术支撑Sora的高级视频生成能力。
大规模训练:在大规模视频数据集上训练,提高模型泛化能力,生成多样化和高质量的视频内容。
零样本学习:能够通过零样本学习执行特定任务,如模拟特定风格的视频或游戏。
应用广泛:适用于社交媒体短片制作、广告营销、原型设计和概念可视化、影视制作等多个领域。
结论
Sora作为OpenAI研发的AI视频生成模型,通过其先进的技术架构和大规模训练,展现了强大的文本到视频的生成能力。它不仅能够生成高质量的视频内容,而且在模拟物理世界和处理复杂场景方面具有显著优势。Sora的应用前景广阔,能够为不同领域的内容创作者和设计师提供强大的支持,推动创意产业的发展。









