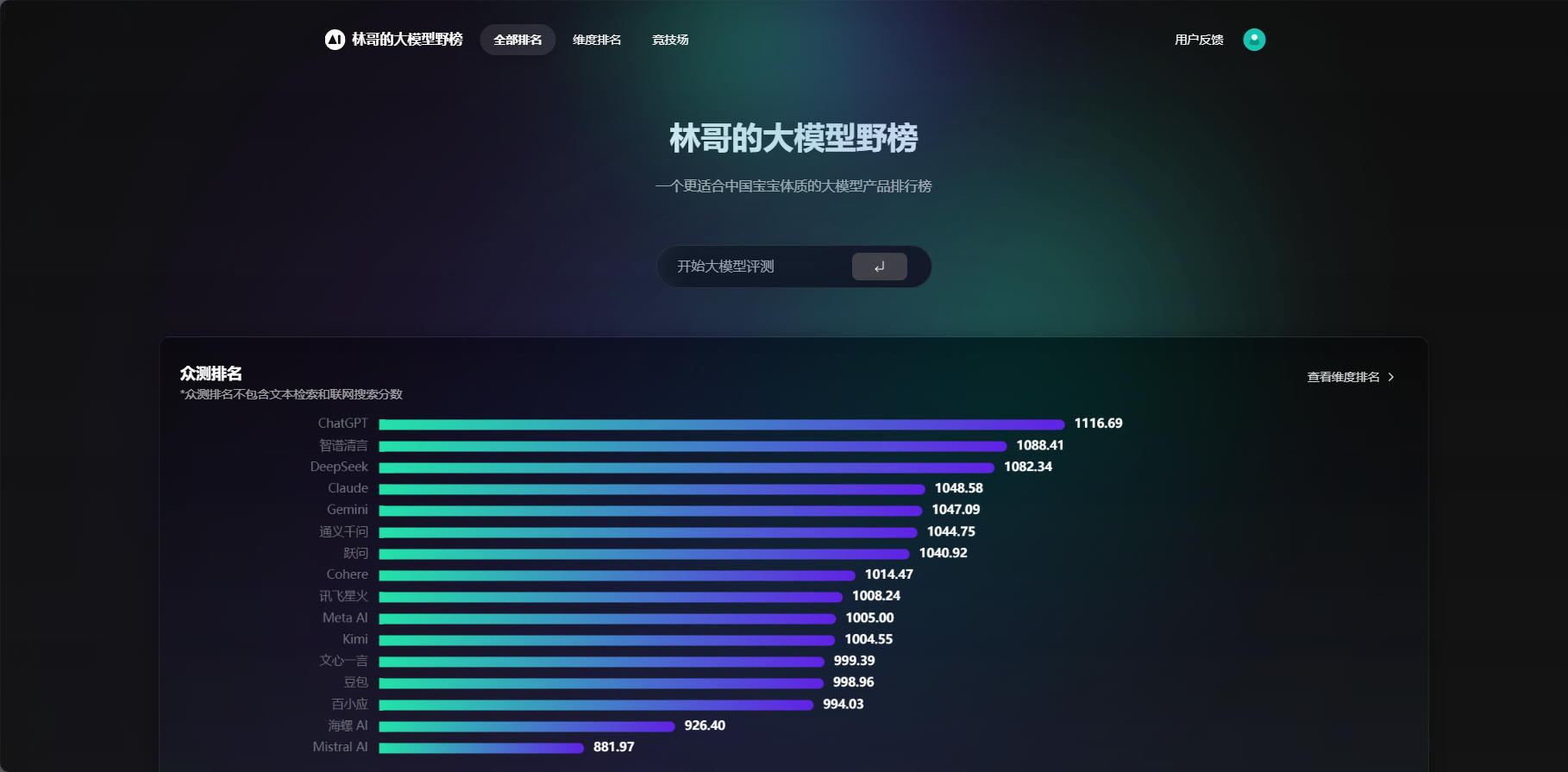
一个直观比较不同大模型在各个维度上表现的工具
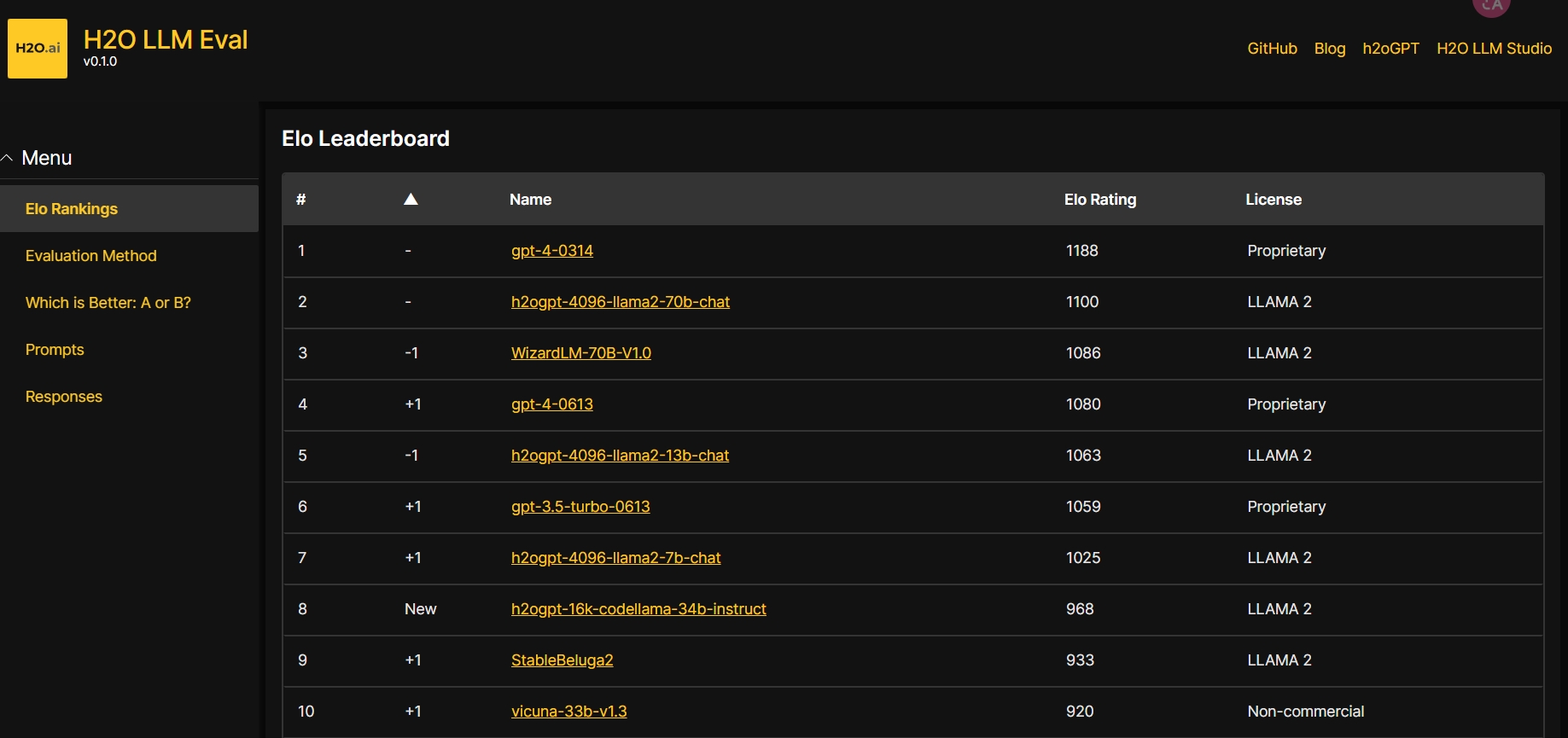
H2O LLM Eval是由H2O.ai开发的一款用于评估和比较大型语言模型(LLM)的工具。它提供...
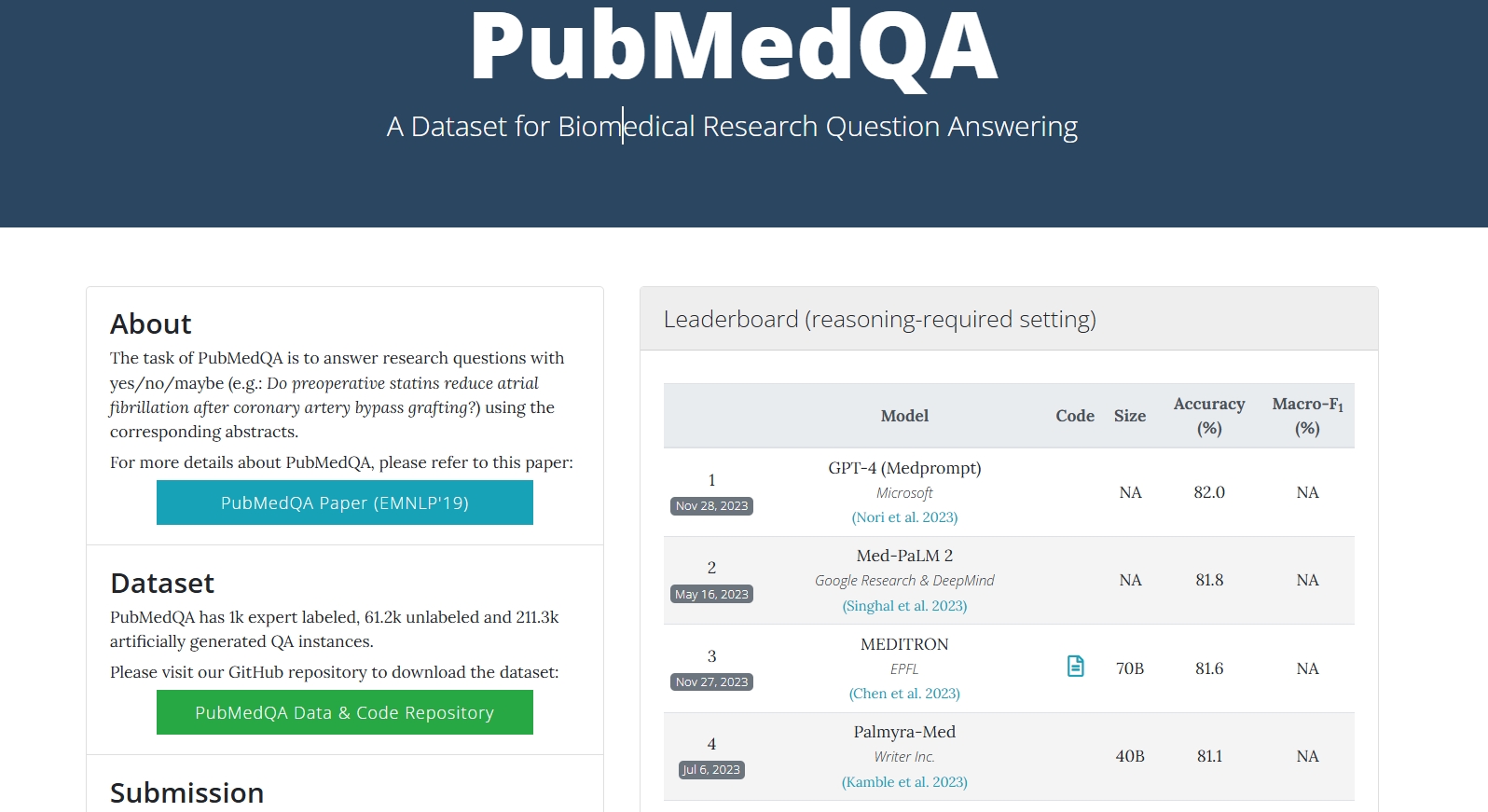
PubMedQA是一个专注于生物医学领域的问答数据集,它从PubMed摘要中收集并构建,用于研究和开...
FlagEval(天秤)是由北京智源人工智能研究院联合多个高校团队共同打造的大模型评测平台。该平台采...
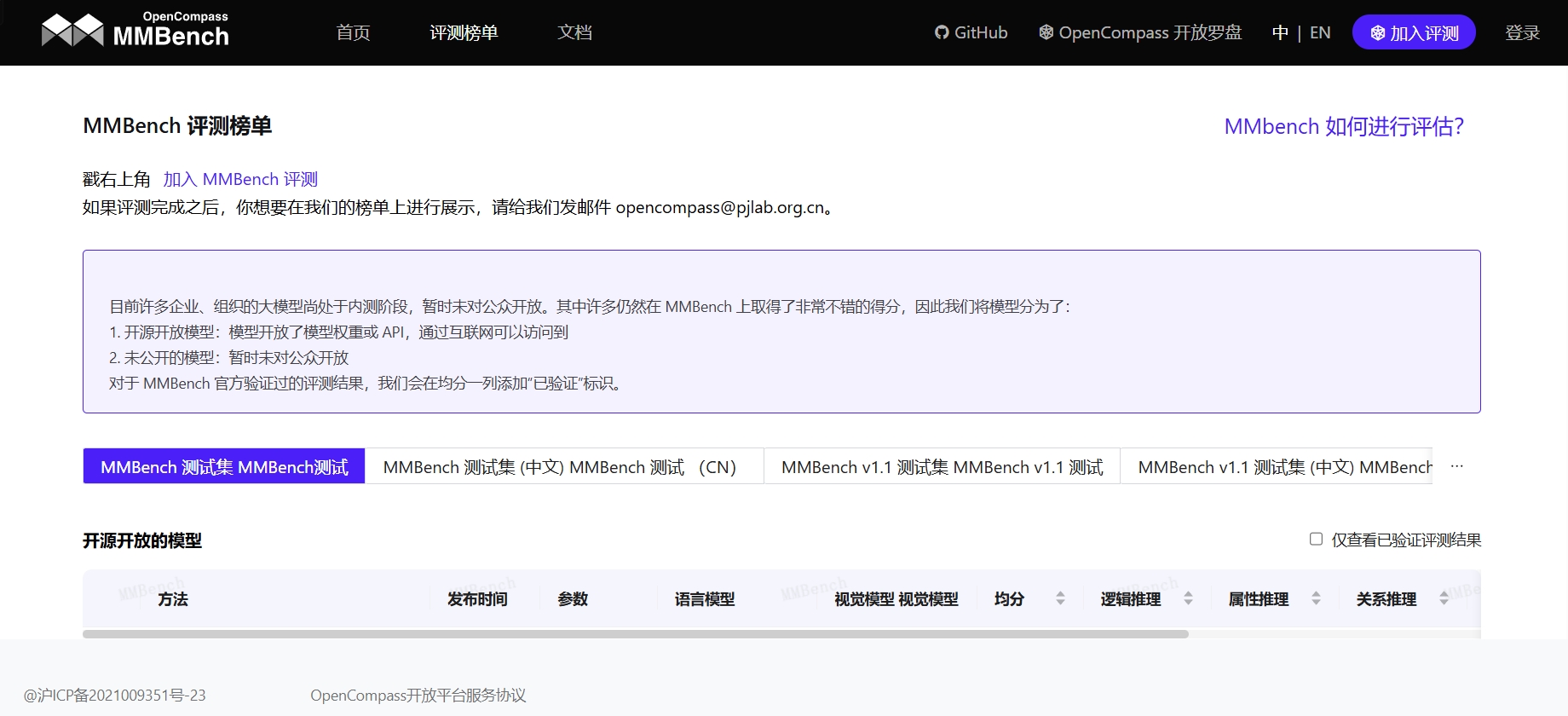
MMBench是由OpenCompass研究团队自建的视觉语言模型评测数据集,旨在实现对大型多模态模...
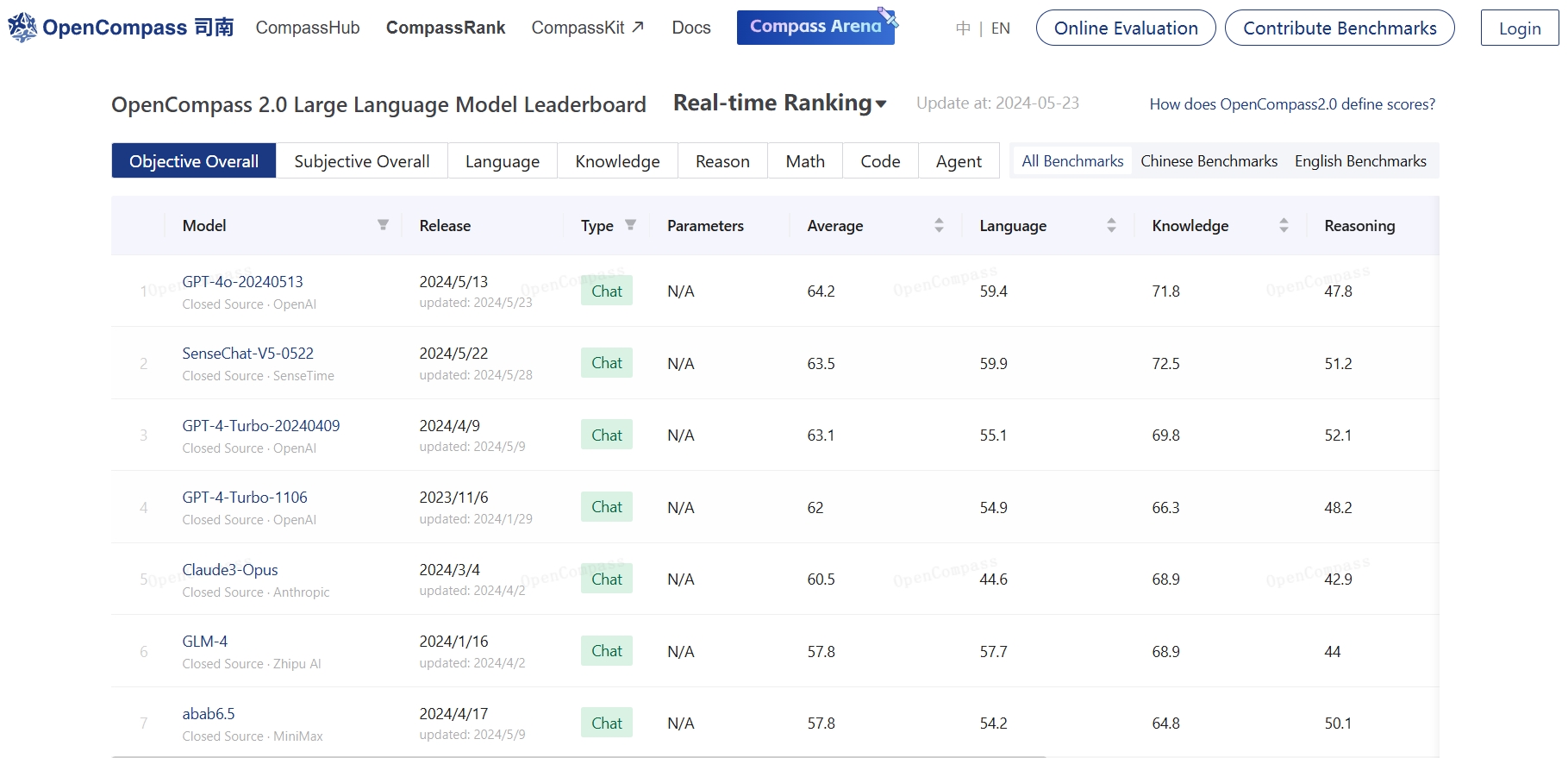
一个用于诊断和提升模型的性能的一站式评测平台
C-Eval是由上海交通大学、清华大学和爱丁堡大学研究人员联合推出的多层次多学科中文评估套件,旨在评...
客服
微信客服
收录
按 ctrl/command+d 一键收藏本网站
回顶部