简介
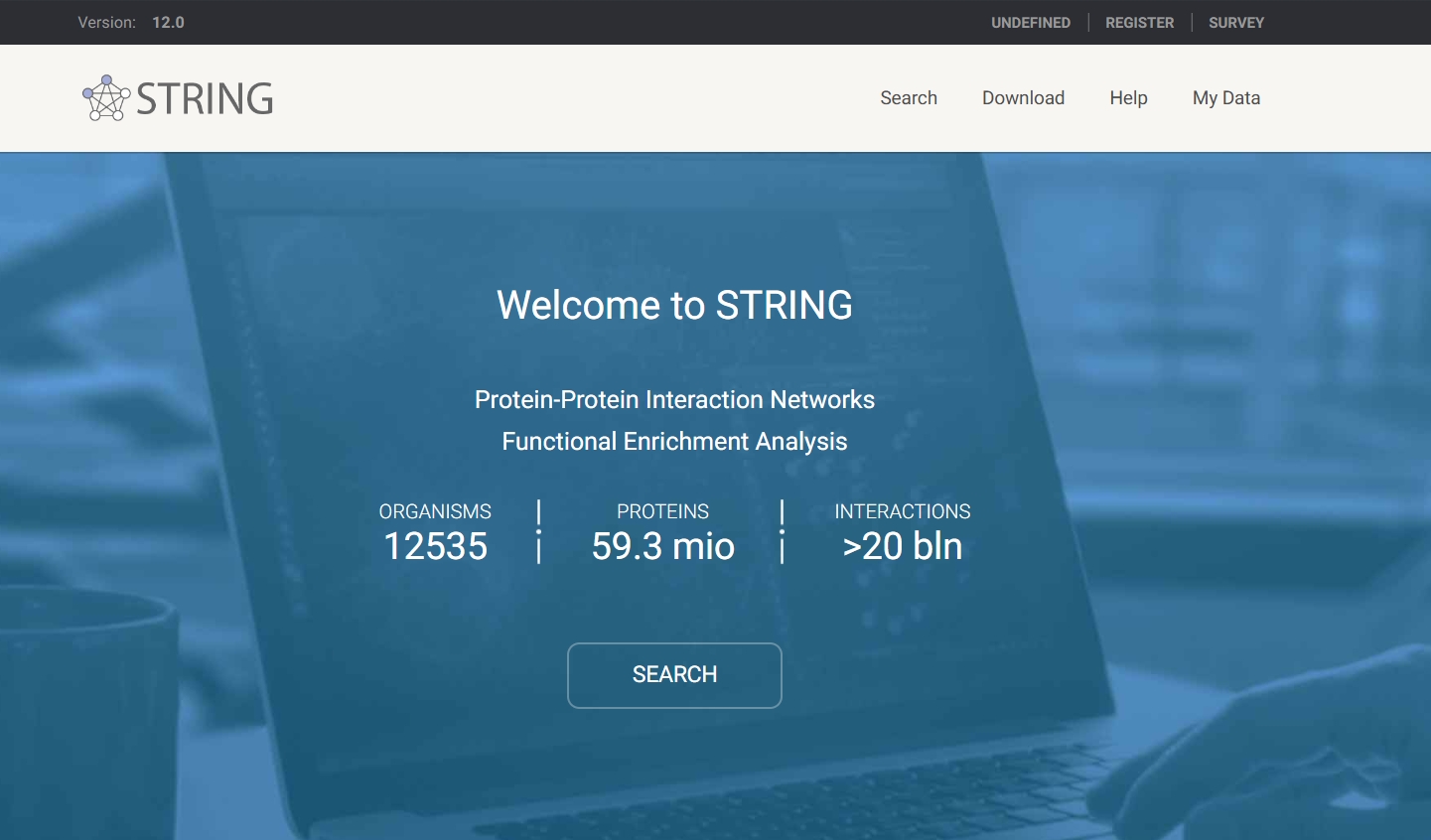
String数据库 是一个广泛使用的生物信息学资源,它专门用于检索已知蛋白质之间的相互作用以及预测新蛋白质的潜在相互作用。这个数据库为研究蛋白质-蛋白质相互作用(PPI)提供了一个强大的平台。
主要功能
蛋白质相互作用检索:用户可以查询已知蛋白质的相互作用,以及预测未知或新发现蛋白质的相互作用。
PPI图生成:String数据库能够生成可视化的蛋白质-蛋白质相互作用图,帮助用户直观理解蛋白质网络。
功能富集分析:提供常见的功能富集分析,如基因本体(GO)和京都基因与基因组百科全书(KEGG)分析,以揭示蛋白质的功能和生物学途径。
公共数据库整合:String数据库基于多个公共数据库和文献信息,包括但不限于UniProt、KEGG、NCBI和Gene Ontology。
全面的数据收集:整合了这些来源的数据,构建了一个全面的蛋白质相互作用网络。
使用方法
用户可以通过输入蛋白质的标识符或名称来检索相互作用信息。
选择感兴趣的蛋白质后,String数据库将展示相关的相互作用网络,并提供网络图的生成选项。
用户可以进一步进行功能富集分析,以深入了解蛋白质的生物学特性和作用。
结论
String数据库是一个宝贵的资源,它通过整合多个公共数据库的信息,为用户提供了一个全面的蛋白质相互作用网络视图。它的功能富集分析工具进一步增强了用户对蛋白质功能和网络的理解。