


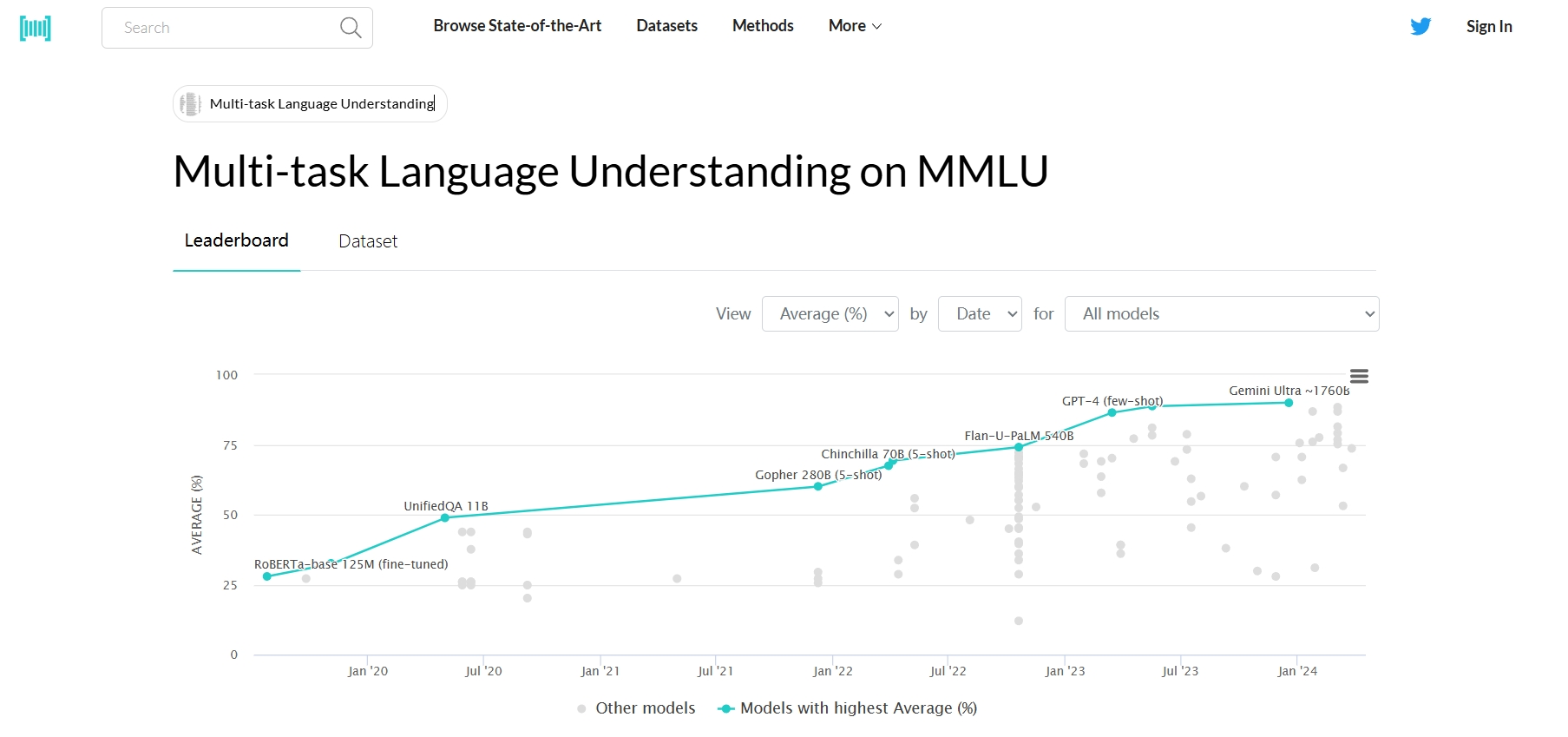
简介
MMLU(Massive Multitask Language Understanding)是一项针对大型语言模型(LLM)的语言理解能力的评估测试。它由加州大学伯克利分校(UC Berkeley)的研究人员于2020年9月推出,是目前最著名的大模型语义理解测评之一。
主要特点
多任务评估:MMLU涵盖57项任务,覆盖初等数学、美国历史、计算机科学、法律等多个领域。
广泛的知识覆盖:测试使用英文,评估大模型的基本知识覆盖范围和理解能力。
零样本和少样本评估:MMLU旨在通过在零样本和少样本设置中评估模型,衡量模型在预训练期间获得的知识。
挑战性:这种评估方式使得基准测试更具挑战性,更接近于评估人类的方式。
多任务准确率:测试衡量文本模型在多任务中的准确率,要求模型具备丰富的世界知识和解决问题的能力。
性能差异:研究发现,尽管大多数模型表现接近随机猜测,但最大的GPT-3模型表现仍比随机猜测好近20个百分点。
改进空间:即使是最好的模型在57个任务中仍需大幅改进才能达到专家级别的准确率。
性能不平衡:模型表现存在不平衡,经常无法判断自己何时出错。
社会重要主题:模型在道德和法律等社会重要主题上的表现仍接近随机猜测。
全面评估:MMLU可以用来分析多任务模型的学术和职业理解的广度和深度,并识别缺陷。
使用场景
语言模型评估:研究人员和开发者可以使用MMLU来评估和比较不同语言模型的性能。
教育和培训:教育机构可以利用MMLU来设计课程和训练材料,提高学生的语言和逻辑思维能力。
技术发展监控:通过MMLU的评估结果,可以监控和理解人工智能技术在语言处理方面的进步。
结论
MMLU作为一项全面的多任务语言理解评估,为大语言模型提供了一个挑战性的测试平台。它不仅有助于推动语言模型的评估标准发展,也为中文语言处理技术的研究和应用提供了重要支持。随着人工智能技术的不断进步,MMLU将继续作为评估和提升LLM性能的重要工具,同时也将促进对模型安全性、偏见和稳健性等更多维度能力的测评。









